

Faster R-CNN, 2015 yılında Shaoqing Ren ve arkadaşları tarafından piyasaya sürülen, bir görseldeki nesneleri tespit etme amacı taşıyan bir çeşit detektördür. Faster R-CNN, R-CNN ailesinin üçüncü üyesidir. Faster R-CNN‘den önce R-CNN, Fast-RCNN gibi nesne algılama amacı taşıyan detektörler kullanılmaktaydı. Faster R-CNN bu detektörlerin devamı niteliğindedir. Faster R-CNN’ye başlamadan önce bazı kavramların ne olduğuna kısaca bakmak konunun anlaşılması açısından faydalı olacaktır.
Peki bu kavramlar nelerdir?
- Görüntü gradyan vektörü
- Yönlendirilmiş gradyanların vektörü (HOG Algoritması)
- Görüntü Segmentasyonu
- Seçici Arama
- Görüntü sınıflandırma için CNN
- Değerlendirme Metriği mAP
- Deforme edilebilir parça modeli
- Overfeat
Görüntü Gradyan Vektörü
Görüntü gradyanını şu şekilde tanımlayabiliriz: Bir görüntüde meydana gelen yoğunluktaki veya renkteki yönlü değişiklik.
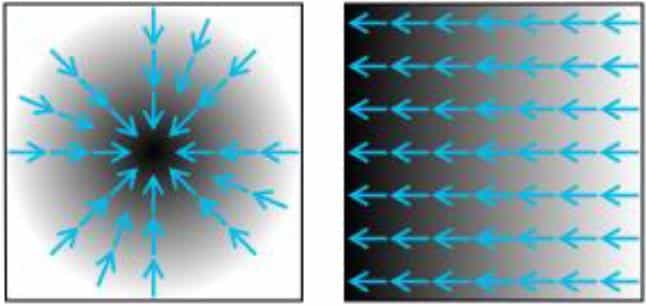
Görüntü gradyan vektörünün yönü açıktan koyuya doğrudur. Konuyu bir görsel ile ifade edecek olursak yukarıda da görüldüğü gibi mavi okların yönü hep açık rengin olduğu kısımdan koyu rengin olduğu kısma doğrudur.
Görüntü gradyan vektörü, en büyük yoğunluk artışının meydana yönü simgeleyen bir çeşit işaretçidir. Buradaki amaç görüntülerden bilgi elde etmektir. Günümüzde en yakın yaklaşım Sobel ve Prewitt kernelleridir.
Yönlendirilmiş gradyanların vektörü (HOG Algoritması)
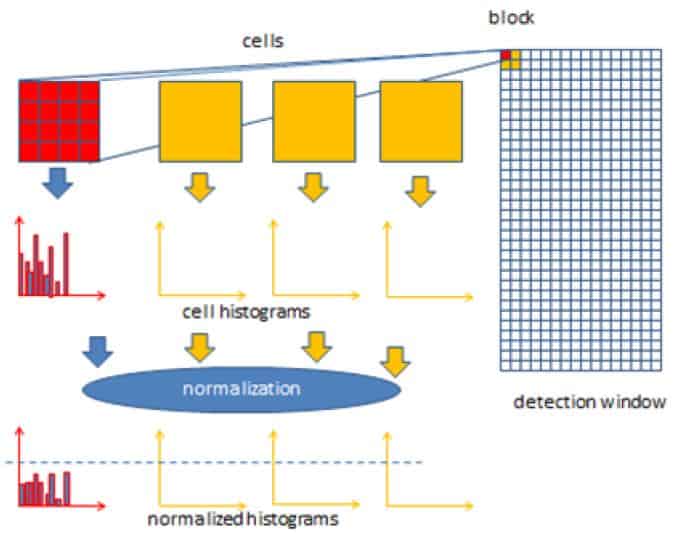
Bu kavramdaki amaç, nesne tanıma sınıflandırıcısı oluşturmak için piksel renklerinden özellik çıkarmaktır. Algoritmanın nasıl bir mekanizması olduğuna üç adımda bakacak olursak:
- Yeniden boyutlandırma ve renk normalleştirme yapılır.
- Her pikselin gradyan vektörü, büyüklüğü ve yönü hesaplanır.
- Görüntü birçok 8×8 piksel hücreye bölünür.
Görüntü Segmentasyonu
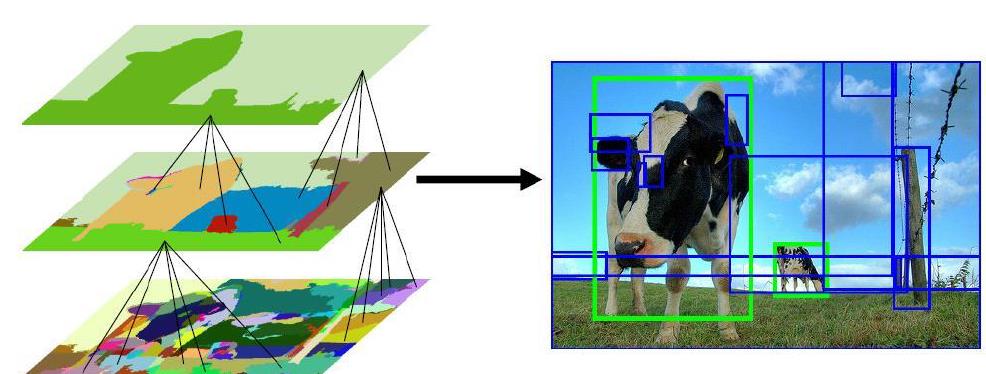
Bir görüntüde birden fazla nesne olduğunda sınıflandırmanın daha etkili yapılmasını sağlamaktadır. İki çeşit yaklaşımı vardır. Bunlardan biri ızgara grafiği yöntemidir, bir diğer yaklaşım ise en yakın komşu grafiği yöntemidir.
Seçici Arama
Potansiyel olarak nesneler içeren bölge önerileri sağlamak için kullanılır. Görüntü bölümleme çıktısının üstüne inşa edilmiştir. Aşağıdan yukarı doğru hiyerarşik bir gruplama yapmak için bölge bazlı özellik kullanmaktadır.
Görüntü Sınıflandırma için CNN
Varlıkları sınıflandırma amacı vardır. Sınıflandırma yapmak için çeşitli evrişim katmanları
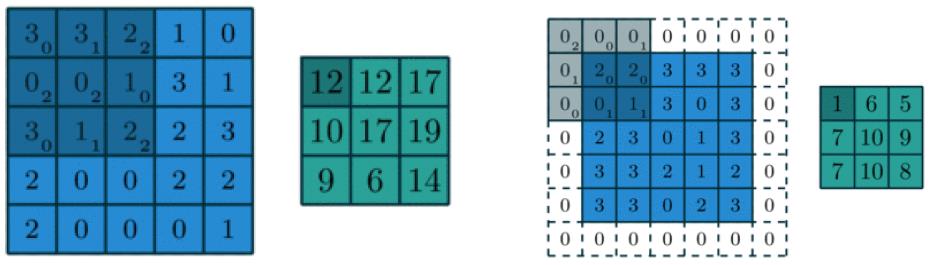
kullanılır. Bir görsel matris haline dönüştürülerek düz bir vektöre dönüştürülür. Aşağıda yer alan 5*5’lik matrisi bir görsel olarak kabul edersek, bu matrise 3*3’lük bir filtre bir adım sağa ve aşağı hareket ederek uygulanır. Her hücredeki sayı ile filtrede yer alan sayı çarpılıp toplanarak çıktı matris elde edilir. Bu adımda çıktı matris ile girdi matris aynı satır ve sütün sayısına sahip olamayacağı için padding (dolgulama işlemi) uygulanır, yani matrisin etrafı sıfırlar ile doldurularak girdi matris ile çıktı matrisin boyutlarının aynı olması sağlanır.
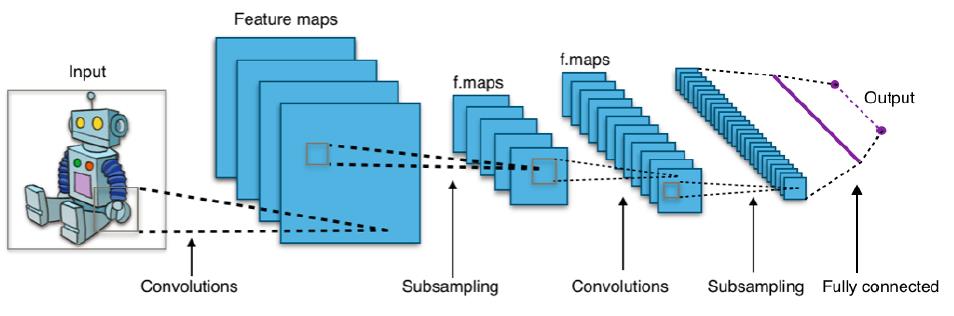
Aşağıda CNN mimarisi görülmektedir. Burada evrişim katmanları, tam bağlı katmanlar (fully conected layers) ve özellik haritaları (feature maps) yer alır. Alexnet, Resnet, VGG, Imagenet gibi çeşitleri vardır.
Değerlendirme Metriği mAP
Nesne detektörlerinin doğruluk oranını ölçen mekanizmadır. Ortalama tahmin anlamına gelir. 0 ile 100 arasında değer alır. Değer 100’e ne kadar yakın olursa doğruluk oranı o kadar yüksektir.
Deforme edilebilir parça modeli
Öğrenme tabanlı nesne algılama amacındaki FPGA IP çekirdeğidir. Mimarisinde SVM ve
HOG algoritmaları kullanılmıştır. Üç ana kısımdan meydana gelmektedir. Bunlar:
- Kök Filtreler (Root Filter): Tüm nesneyi kaplayarak bir bölge özelliği için ağırlık belirtir.
- Parçalı Filtreler (Part Filters):Kök filtreye oranla iki katı çözünürlükte öğrenme gerçekleştirir.
- Uzamsal Model (A Spatial Model):Köke göre parça filtrelerin konumlarını puanlar.

Aşağıda görülen formüldeki,
- X:Belirli bir konuma ve ölçeğe sahip görüntüdür.
- Y: X’in bir alt bölgesidir.
- 𝛽𝑟𝑜𝑜𝑡:kök filtre
- 𝛽𝑝𝑎𝑟𝑡: parça filtre
- Cost( ):Köke göre ideal konumdan sapan parçanın mesafesini ölçen fonksiyondur.

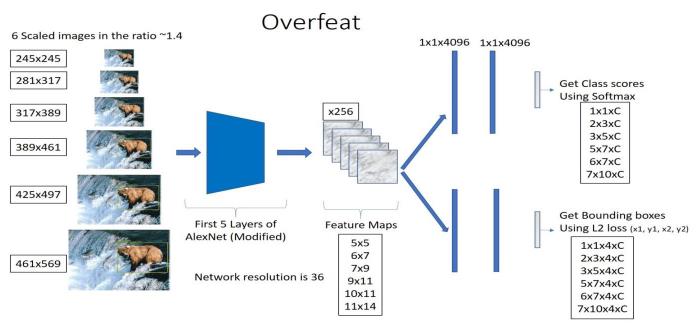
Overfeat
Evrişim, havuzlama, tam bağlı katmanları bulunan klasik bir evrişimli sinir ağı mimarisidir. Amacı potansiyel olarak nesnenin bulunduğu yerlere sınırlayıcı kutular (bounding box) çizmektir. Alexnet mimarisi ile çok benzemektedir.
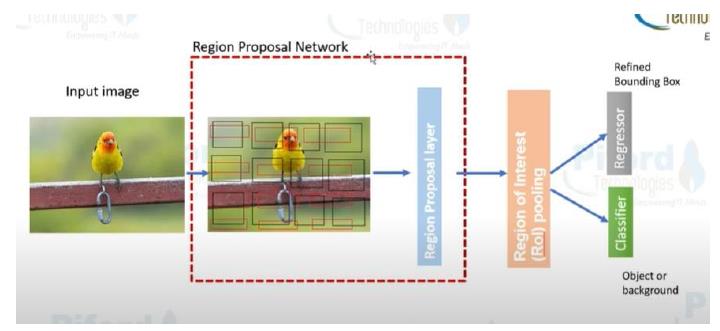
Faster R-CNN’nin mimarisine kısaca bakarsak temelde iki ana kısımdan oluşmaktadır. Bunlar RPN (Bölgesel Öneri Ağı) ve RoI Pooling (İlgi Alanı Havuzlama) katmanlarıdır. RPN
katmanına bakacak olursak temelini anchor boxlar oluşturmaktadır. Peki anchor box nedir?
Anchor box, bir görüntüdeki farklı boyutlardaki nesnelerin muhtemel konumlarını tespit
etmek için kullanılan kutulardır. Farklı boyutlardaki nesnelerin tespitindeki kullanıldıkları için
farklı boyutlarda olabilmektedir. Bunu bir örnek ile inceleyecek olursak:

Buradaki görselde uçak küçük boyutlara sahip olduğu için uçağı tanımlarken küçük boyutta
bir anchor box tercih ederiz. Ancak görseldeki yelkenli uçağa oranla daha büyük bir alan
kapladığı için büyük boyutlara sahip olan bir anchor box tercih ederiz. Anchor boxun ne olduğundan söz etmişken IoU değerinden söz etmemek olmaz.

Buradaki nesneyi araba olarak kabul edersek arabanın tam konumunu tanımlamak için sarı sınırlayıcı kutunun kullanıldığı, tahmini olarak arabanın olabileceği konumu belirtmek için ise yeşil renkli sınırlayıcı kutunun yer aldığını görürüz. İşte bu iki kutunun kesişim noktası
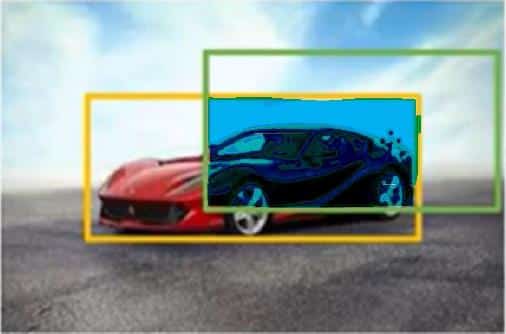
mavi ile tanımlanan alan anchor boxu ifade eder. Bu anchor boxun içerisinde nesnenin olup olmamasının ölçütü ise IoU değeridir. IoU değeri %70’ten daha bir büyük bir orana sahip ise burada bir nesnenin bulunma olasılığı yüksektir. %30’dan daha düşük bir değerde ise burada nesnenin bulunma ihtimalinden söz etmek mümkün değildir.
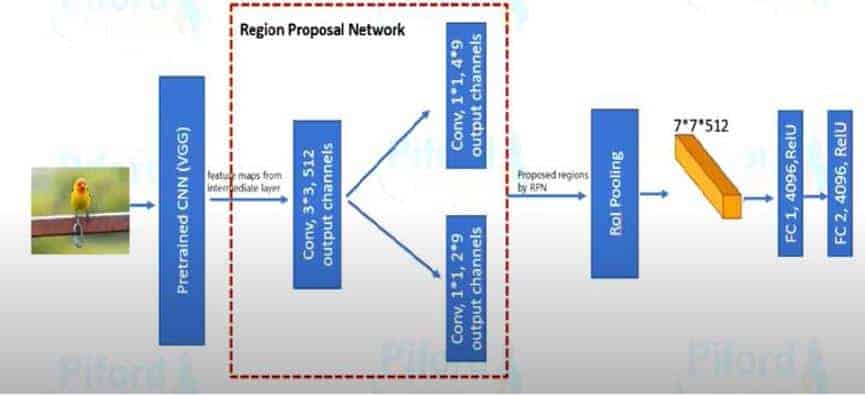
Yeniden RPN’ye dönecek olursak bir görüntünün direk RPN katmanına girmesi mümkün değildir. Öncelikle bir hazırlık katmanından geçmelidir. Buradaki hazırlık katmanını VGG sağlar. VGG yerine herhangi bir CNN mimarisi (Alexnet, Resnet, Imagenet) kullanabilirsiniz. Burada VGG’nin amacı sınıflandırma yapmak değil, görüntüyü özellik haritalarına dönüştürerek (feature maps) RPN katmanı için hazır hale getirmektir. Görüntü VGG’den geçtikten sonra RPN katmanında 3*3lük bir filtreye 512 tane evrişim katmanına maruz kalır. Daha sonra iki yola ayrılır. Bunlar: sınıflandırma (classifier) ve regresyon (regressor) katmanlarıdır. Görüntü öncelikle sınıflandırma katmanına gelir.
Burada amaç sınıflandırma yapmak değil, potansiyel bölgede nesnenin olup olmama durumunu belirtmektir. Bunun için ikili (binary) sistem kullanılır. Buradaki iki rakamı onu ifade etmektedir. (1:nesne var, 0:nesne yok). 9 rakamı ise görselin 9 adet anchor boxa yani 9 bölgeye ayrıldığını ifade eder. Bu rakam değişmez, yani görsel her zaman aynı sayıda bölgeye ayrılır ve 1*1’lik bir filtre uygulanır. Eğer nesne varsa 1 doğruluk değerini alarak regresyon katmanına geçer. Regresyon katmanının amacı sınırlayıcı kutu (bounding box )çizmektir. Bunun için 1*1’lik bir filtre uygulanır. Bu aşamadaki 9 rakamı sınıflandırma katmanı ile aynı işi yapar. 4 rakamı ise sınırlayıcı kutunun koordinatlarını (sınırlayıcı kutunun merkez noktasının x ve y koordinatları, sınırlayıcı kutunun yüksekliği, sınırlayıcı kutunun eni) ifade eder.
RPN katmanından çıkan görüntü şimdi de RoI katmanına geçiş yapar. RoI katmanının iki adet girdisi vardır. Bunlardan biri VGG katmanından çıkan özellik haritaları (feature maps) bir diğeri ise RPN katmanından çıkan farklı boyutlara sahip alanlardır. Burada alanların farklı boyutlara sahip olmasının sebebi ise, anchor boxu anlatırken de bahsetmiş olduğum, görüntüdeki farklı boyutlara sahip olan nesnelerdir. RoI katmanının amacı ise farklı boyutlardaki alanları max pooling kullanarak aynı boyutlara sahip özellik haritalarına (feature maps) dönüştürmektir. Bu işlemi yaparken de 7*7 boyutlarına sahip bir filtre ve 512 evrişim katmanı kullanır.
Çeşitli fonksiyonlardan da geçtikten sonra görüntü yine bir ayrıma girer. Bunlar: Softmax sınıflandırma (softmax classifier) ve regresyon (regressor) katmanıdır. Bu kısım RPN’deki kısım ile benzerlik gösterir. Softmax sınıflandırma birden dazla nesnenin olduğu görüntüdeki nesnelerin sınıflandırmasını yaparken regresyon katmanı sınırlayıcı kutu (bounding box ) çizme işini yapar. Faster R-CNN mimarisinin çalışma mantığı kısaca bu şekildedir.