

Reinforcement learning, makine öğrenmesinin alt dallarından biridir. Türkçeye pekiştirmeli öğrenme ve takviyeli öğrenme olarak çevrilmiştir. Bu yazıda reinforcement learning yerine pekiştirmeli öğrenme ifadesini kullanacağım.
Pekiştirmeli Öğrenme
Makine öğrenmesinin alt dalları olan denetimli ve denetimsiz öğrenmeyi günlük hayatımızda denk gelme olasılığımız fazla iken pekiştirmeli öğrenme hayatımıza yeni yeni giren bir makine öğrenmesi çeşididir. Keşfedilmesi 1989 yılına dayanırken diğer makine öğrenmesi çeşitlerine göre daha az bilinmesinin sebebi kullanım alanının günümüzde sınırlı olmasıdır. Yakın zamanlarda adını sık sık duyacağımız bu alana detaylı bir şekilde bakmadan önce konuyla ilgili bazı kavramlara birlikte bakalım.
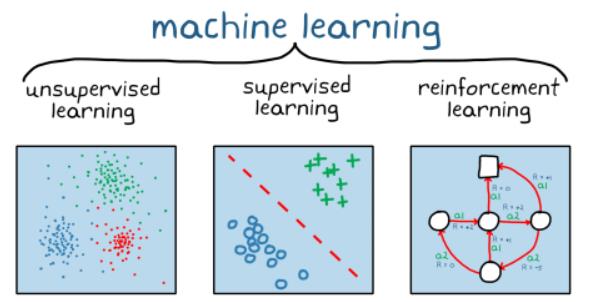
Makine Öğrenmesi: Veri ve algoritmaları kullanarak insanın öğrenme mekanizmasını taklit eden bir yapay zeka dalıdır.
Denetimli Öğrenme (Supervised Learning): Etiketli verilerden eğitim ve test kümesi oluşturarak eğitim kümesinden bir model oluşturulmasını sağlayan ve modelin performansını test kümesi üzerinden ölçen makine öğrenmesi çeşididir. Sınıflandırma ve regresyon problemlerinde kullanılır.
Denetimsiz Öğrenme (Unsupervised Learning): Etiketlenmemiş verileri benzer yönlerden kümeleyen makine öğrenmesi dalıdır. Kümeleme problemlerinde kullanılmaktadır.
Pekiştirmeli öğrenme, bir ajanın kendi eylemlerinden ve deneyimlerinden aldığı geri bildirimleri kullanarak deneme yanılma yoluyla maksimum ödüle ulaşmayı hedefleyen makine öğrenmesi tekniğidir. ilginizi çekebilir: Mask R-CNN: Bir Nesne Tanıma Algoritması
Günlük hayatta bir insan saatlerce çalıştıktan sonra yorgunluk hisseder, bu durum açlık ve dikkat seviye olarak iki parametreye bağlı olsun. İnsan vücudu bu iki parametreyi değerlendirerek dinlenmeye karar verir. Aynı durumu mobil çöp toplama robotu için de düşünürsek robot bir sonraki odadaki çöpü toplamak için şarj seviyesine ve odayla olan mesafesine bakarak odayı temizleyip temizlememeye karar verir. Bu iki örnek pekiştirmeli öğrenmeyi özetlemektedir.
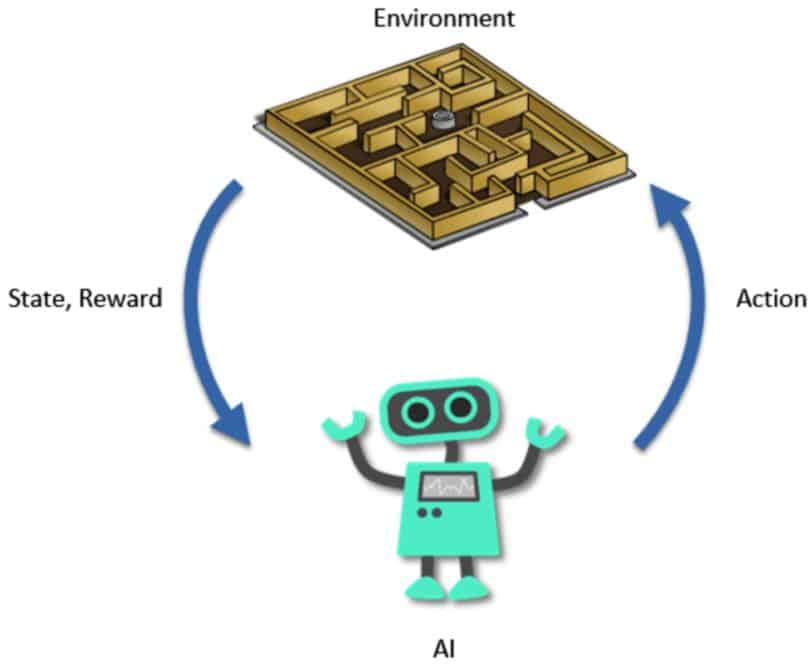
Pekiştirmeli öğrenmede çevre (environment) ve ajan (agent) iki önemli unsundur. Mobil çöp toplama robotu örneğinde robot ajanı temsil ederken içinde bulunduğu ortam ise çevreyi temsil etmektedir.
Pekiştirmeli öğrenmeyi belirli bir çerçevede anlatmak mümkündür. Bu çerçevede kullanılan bazı unsurlar ve unsurların yerine getirdiği bazı görevler vardır.
Pekiştirmeli Öğrenme Unsurları
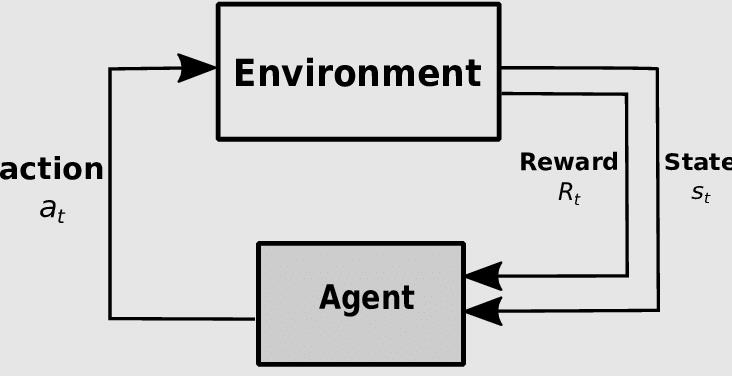
- Ajan (agent) :Çevreden aksiyonları alan yapıdır. Ajanı bir insan veya robot olarak tanımlamak doğru bir yaklaşım değildir. Ajan farklı örneklerde bir algoritma da olabilir.
- Çevre (environment): Ajanın gerçekleştirdiği eylemlere karar verdiği ve öğrendiği ortamdır.
- Aksiyon (action): Ajanın gerçekleştirdiği eylemlerdir.
- Ödül (reward): Ajanın başarısının veya başarısızlığının bir ölçüsüdür.
- Durum (state): Ajanın çevredeki anlık durumudur.
Pekiştirmeli öğrenme konusunun anlaşılması için bazı kavramların bilinmesi veya hatırlanması gerekir. Şimdi hep birlikte bu kavramları inceleyelim.
Politika (Policy): Ajanın aksiyonlara karşı vereceği tepkiyi belirler. Karar verme stratejisi olarak da tanımlanabilir.
Değer İşlevi (ValueFunction):Ajanın içinde bulunduğu durumu ve durumdan başlayarak belirli bir politikayı yürütmesi sonucu elde edilen uzun vadeli ödüldür.
Fonksiyon Yaklaşımcısı (Function Approximator): Eğitim örneklerinden bir fonksiyon çıkaran problemi ifade eder. Standart yaklaşımcılar karar ağaçlarını, sinir ağlarını ve en yakın komşu metodunu içerir.
Ayrık Eylem Uzayı (Discrete Action Space): Bir ajan sonlu bir eylem kümesinden hangi eylemin farklı gerçekleşeceğine ayrık eylem uzayı ile karar verir.
Devamlı Eylem Uzayı (Continuos Action Space): Eylemler tek gerçek değerli bir vektörle ifade edilir.
Model: Durum-aksiyon çiftlerinin durumlar üzerindeki olasılık dağılımlarını haritalayan ajanın çevredeki bakış açısıdır.
Dinamik Programlama (Dynamic Programming): Bir bileşimsel maliyet yapısı ile sıralı karar problemlerini çözmek için kullanılan bir çözüm metodu sınıfıdır.
Monte Carlo Yöntemleri (Monte Carlo Methods): Bir durum değerini o durumdan başlayarak birçok deneme yaparak tahmin eden ardından bu denemelerden alınan toplam ödüllerin ortalamasını alan değer işlevlerini öğrenmeye yönelik bir yöntem sınıfıdır.
Geçici Fark Algoritmaları (Temporal Difference (TD) algorithms): Geçici olarak ardışık tahminleri karşılaştırma fikrine dayanan bir öğrenme yöntemleri sınıfıdır.
Markov Karar Süreçleri (Markov Decision Process (MDP)): Bir ortamı tanımlayan matematiksel çerçevedir. Aşağıda görülen şekil ile pekiştirmeli öğrenmeyi markov karar süreci ile ifade etmek mümkündür.
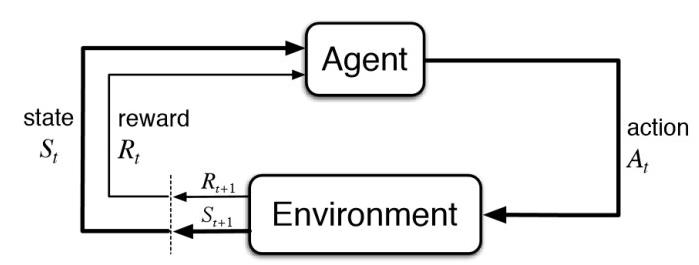
Ajan ve çevre her t süre adımında etkileşir. Her zaman adımında ajan, ortam durumu (St) hakkında bilgi alır. St’ye bağlı olarak t anında ajan bir aksiyon (At) seçer. Takip edilen anlarda ajan ayrıca sayısal ödül sinyali (R t+1) alır. Böylece S0,A0,R1,S1,A1,R2 gibi bir dizi oluşur. Rastgele değişkenler Rt ve St iyi tanımlanmış ayrık olasılık dağılımına sahiptir. Bu olasılık dağılımları Markov karar süreci sayesinde yalnızca önceki duruma ve aksiyona bağlıdır.
S:durum, A:aksiyon, R:ödül kümesi olursa olasılık St, Rt, At değerleri s’, r ve a değerlerini alarak bir önceki durum için aşağıdaki fonksiyondaki gibi ifade edilir.

Fonksiyon P dinamik programlamayı kontrol etmektedir.
Pekiştirmeli öğrenmeyi model kullanılan pekiştirmeli öğrenme ve modelsiz pekiştirmeli öğrenme olmak üzere ikiye ayırabiliriz. Aşağıdaki tabloda da bu ayrım net bir şekilde görülmektedir. Ben bu yazıda modelsiz pekiştirmeli öğrenmenin alt dalları olan politika optimizasyonundan ve q öğrenme yapısından bahsedeceğim.
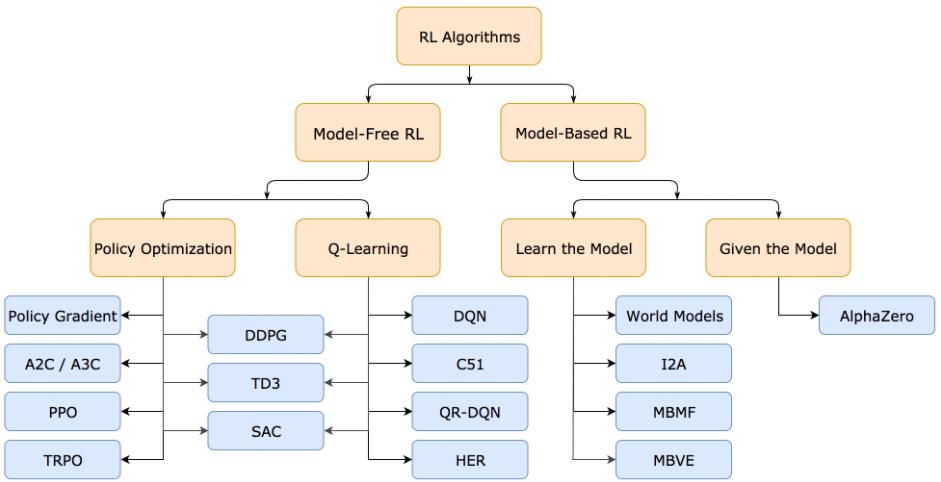
Model Bazlı Pekiştirmeli Öğrenme (Model-Based RL): Çevredeki geçişlerin ve anlık sonuçların içsel bir modelini oluşturmak için deneyimleri kullanır. Arama ve planlama ile uygun aksiyonlar modelde seçilir.
Modelsiz Pekiştirmeli Öğrenme (Model-Free RL): Bir model kullanmadan veya tahmin yapmadan da durum/aksiyon değerlerini veya politikalardan birini ya da her ikisini doğrudan öğrenmek için deneyimi kullanır. Modelsiz yöntemler modelin kullanıldığı yöntemlere göre istatiksel olarak daha az etkilidir. Bunun sebebi ise çevreden gelen bilgiler doğrudan kullanılmadan, önceki ve hatalı olabilen durum değerleriyle ilgili tahminler veya inanışlarla birleştirilir.
Politika Optimizasyonu (Policy Optimization): Ajan, durumu ve aksiyonu eşleyen politika fonksiyonundan direk olarak öğrenir. Politika, değer işlevi kullanılmadan belirlenir. İki çeşit politika vardır.
Deterministik Politika: Durumu belirsizlik olmadan aksiyona eşler.
Stokastik Politika: Belirli bir durumdaki eylemler üzerinde olasılık dağılımı verir. Bu sürece “kısmen gözlenebilir markov süreci” de denilebilir.
Politika Gradyanı (Policy Gradient): Bu yöntemde Ɵ adında parametresi olan π politikası vardır. π, aksiyonun olasılık dağılımını çıktı olarak verir. Sonra en iyi Ɵ parametresine ulaşmak için bir skor fonksiyonu olan J(Ɵ) maksimum yapılır. Bu da discount faktörü (Ɣ) ve ödül (r) ile yapılır. Formülü aşağıda görülmektedir.
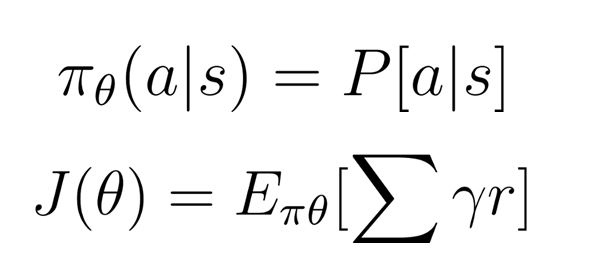
Ana adımlar şu şekilde özetlenebilir:
- Politika skor fonksiyonu ile politikanın kalitesi ölçülür.
- Politikayı geliştirecek en iyi parametreyi bulmak için politika gradyan yükselişi kullanılır.
Q Öğrenme (Q Learning):
Q öğrenme, Q(s,a) aksiyon değer fonksiyonunun belirli bir durumda nasıl iyi aksiyon alacağını öğrenir. Kısaca s durumu verilen bir eylem üzerine bir skaler değer olarak atanır. Q öğrenmenin adımlarında Q tablosu yer alır.
Q Tablosu: Her durumda her aksiyon için maksimum beklenen gelecekteki ödül için oluşturulan tablodur. Burada politika uygulanmaz. Sadece Q tablosunun daima en iyi aksiyonu seçmesi geliştirilmek istenir.
Q tablosunu oluşturmak için Q algoritması bilinmelidir. Peki Q algoritması nedir?
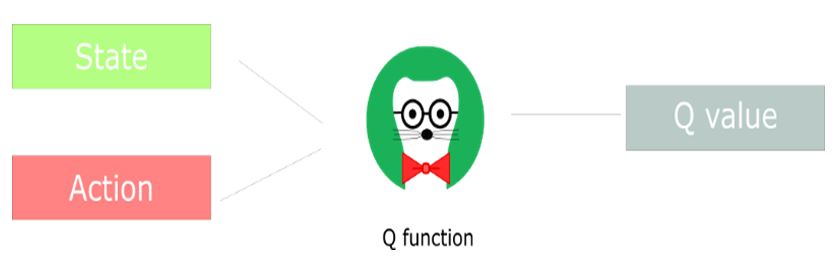
Q algoritması, durum ve aksiyonu girdi olarak alır ve beklenen gelecekteki ödülü her durumdaki aksiyonda döndürür. Aşağıda yer alan formülde de bu durum görülmektedir.
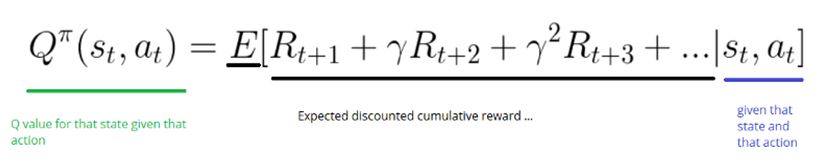
Q fonksiyonu, durum ve aksiyonla ilgili satırı ve sütunu bulmak için Q tablosunda kaydırılır. Q tablosu başlarda 0 değerini döndürür. Çevre keşfedildikçe daha iyi sonuçlar alınır. Bunu da Q(s,a)’yı Bellman eşitliğine göre sürekli güncelleyerek yapar.
Bellman Eşitliği (Bellman Equation):
Bu denklemi aşağıda görülen şekildeki gibi inceleyebiliriz.
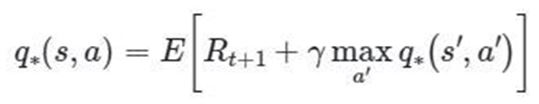
Optimal aksiyon-değer fonksiyonu q* ile gösterilmiştir. t zamanda,
- (s,a): aksiyon-durum çifti
- s:başlangıç durumundan beklenen dönüş
- a:alınan aksiyon
- Rt+1:optimal politika ile daha sonra beklenen ödül
- (s’,a’): potansiyel bir sonraki durum-aksiyon çiftini temsil eder.
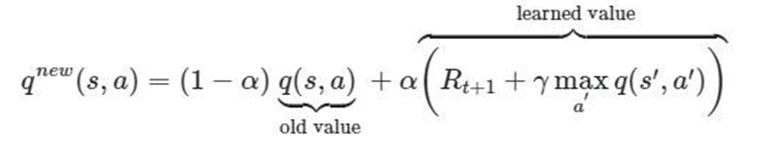
Q değer güncellemesi ise yukarıda şekilde görülen denklem ile yapılır. Q öğrenmenin adımlarını şu şekilde sıralayabiliriz:
- Öncelikle Q tablosu oluşturulur.
- Bir aksiyon seçilir.
- Aksiyon yapılır.
- Elde edilen ödülün miktarı ölçülür.
- Q tablosu güncellenir.
Bu aşamaların sonunda iyi bir q tablosu elde edilir.

Derin Q Öğrenme (Deep Q Learning):
Derin Q öğrenme, Q öğrenme ile sinir ağlarının birlikte kullanımıdır. Q tablosunun çok karışık olduğu durumlarda ve büyük durum uzayı ortamlarında derin q öğrenme kullanılmaktadır. Q tablosu yerine sinir ağlarının durumuna bağlı olarak her aksiyon için yaklaşık Q değerleri verir.
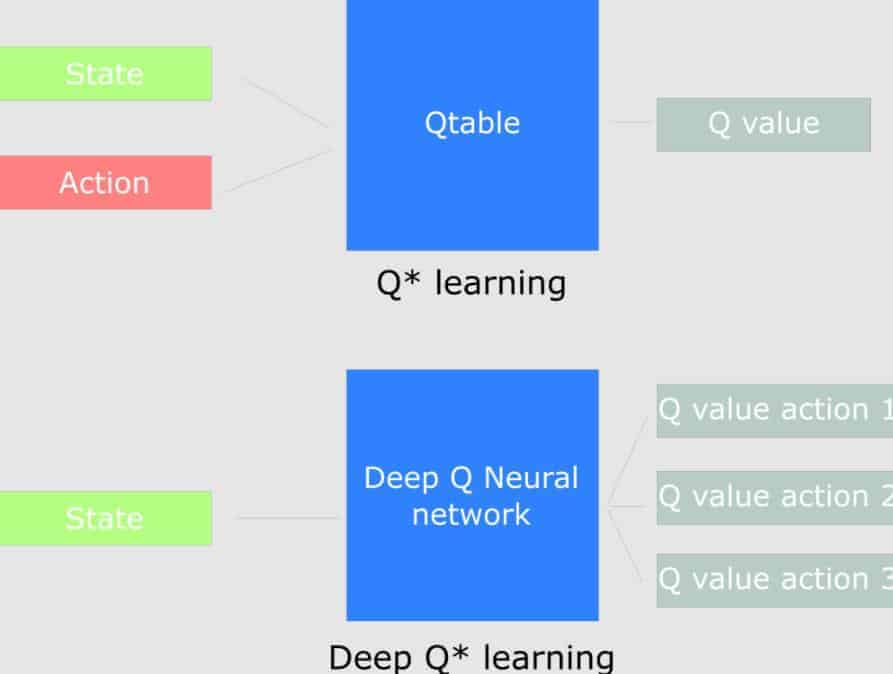
Derin q öğrenme mimarisi girdi olarak dört karelik bir yığın alır. Bunlar ağdan geçerek verilen durumda mümkün olan her aksiyon için bir Q değerleri vektörü döndürür. En iyi aksiyonu bulmak için bu vektörün en büyük Q değeri alınmalıdır. Başlangıçta ajan kötü sonuçlar alır ancak daha sonra durumları yapılacak en iyi aksiyonlarla ilişkilendirir.

Derin Q öğrenme mimarisini dört ana adımda inceleyelim.
1. Ön İşleme (Preprocessing part):
Eğitim için gereken hesaplama süresi azaltılır. Bu adımı Frozen Lake oyununda görelim.
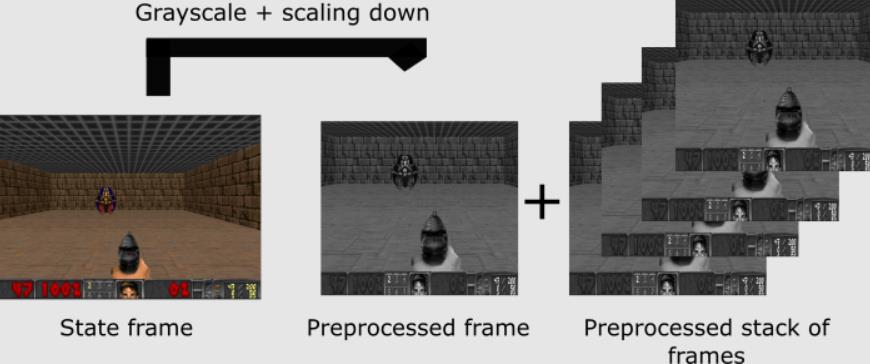
Oyundaki amaç hedefi vurmaktır. Hedefi vurmak için görselin renkli olmasına gerek yoktur. Durumların hepsi 3 kanallı RGB’den gri olan 1 kanala düşürülür. Aynı zamanda hedefi görmek için tavana da ihtiyaç yoktur. Çerçeveyi (tavanı) keseriz. En son adımda ise çerçeve boyutu küçültülerek 4 alt çerçeve bir araya getirilir.
2. Zamansal Sınırlama Sorunu (The problem of temporal limitation):
Bu aşamada çerçeveler bir araya yığılır. Bu aşamayı incelemek amacıyla Pong oyununa bakalım.

Oyundaki amaç, kare kutunun iki levha arasında dengede kalıp düşmemesine dayanır. Yukarıdaki görsele baktığımız zaman kare kutunun hangi yöne (sağ veya sol) hareket ettiğini görmemiz mümkün değildir. Aynı durum ajan için de geçerlidir. Ajan tek bir çerçeveye bakarak nesnelerin nerede ve ne kadar hızlı olduğunu belirleyemez. Bunun için birden fazla çerçeve aşağıda görüldüğü gibi bir araya getirilir.

Bu görsele bakıldığı zaman kare kutunun sağa doğru hareket ettiğini söyleyebiliriz.
3. Evrişim Ağlarını Kullanma (Using convolution networks):
Çerçeveler üç evrişim katmanında işlenir. Bu katmanlar görüntülerdeki uzamsal ilişkilerden yararlanmamıza izin verir. Her evrişim katmanı bir etkinleştirme işlevi olarak ELU‘yu kullanır.
ELU (Exponential Linear Unit): Derin sinir ağlarında öğrenmeyi hızlandıran ve daha yüksek sınıflandırma doğruluklarına yol açan “üssel doğrusal birimdir”.
Son adım anlatımında sorun ve çözüm şeklinde ilerleyelim.
4. Deneyim Tekrarı (Experience Replay):
Bu adım iki şeyi halletmemizi sağlar:
1.Önceki deneyimleri unutmamak
Sorun: Çevre ile etkileşimlerden sinir ağı sıralı örnekler alır. Bunun üzerine yeni deneyimler yazarken önceki deneyimleri unutmaya meyillidir.
Çözüm: Tekrar arabelleği oluşturulur. Bu depolar çevre ile etkileşime girerken demetleri deneyimliyor. Sonra sinir ağını beslemek için bir demet tuple örneklenir.
2.Deneyimler arası kolerasyonu azaltmak
Sorun: Her aksiyonun bir sonraki durumu etkilemesi yüksek oranda ilişkilendirilebilen bir dizi deneyim demeti oluşur.
Çözüm:
- Ağ sıralı eğitilirse ajanın kolerasyondan etkilenmesi azalır.
- Tekrar arabelleğinden rastgele örnekleyerek kolerasyon kırılabilir. Bu aksiyon değerlerinin yıkıcı bir şekilde salınmasını ve uzaklaşmasını önler.
Şimdi de pekiştirmeli öğrenmenin kullanıldığı platformlara bakalım.
Pekiştirmeli Öğrenme Algoritmalarının Kullanıldığı Platformlar
1. DeepMind Lab:

Zengin simüle edilmiş ortamlarda aracı tabanlı yapay zeka araştırmaları için oluşturulmuş, açık kaynaklı 3B oyun benzeri bir platformdur.
2. Project Malmo:

Yapay zekadaki temel araştırmaları desteklemek amacıyla kurulan bir yapay zeka platformudur.
3. OpenAI GYM:

Pekiştirmeli öğrenme algoritmaları oluşturmak ve karşılaştırmak amacıyla kullanılan bir araç takımıdır.
Konunun kapanışını Google’ın pekiştirmeli öğrenme kullanarak oluşturduğu parkur ile kapatalım.
